How-To Guide : JEDI Evaluation Run
In this guide, we illustrate with the help of the comprehensive example on how to perform a JEDI evaluation run and generate the corresponding report. We note that this is not the only way to approach the task, but it is the one we have tested. Conforming with the requirements, for our comprehensive case, we want to do two strong scaling runs on JEDI and JURECA.
We have divided the guide into the sections for easier reading:
Preparing your JUBE file
The first step is to prepare your JUBE file for the evaluation runs.
We start with the jedi branch of the
comprehensive example.
We see here
that we have added two new tags for our evaluation runs,
jedi.evaluation.jedi for running on JEDI and
jedi.evaluation.jureca for running on JURECA. These tags have been
introduced since release of v3 branch
of exacb in order to make it easier to use the same JUBE file for different
runs for evaluation.
Preparing your CI file
Now that our JUBE file is ready, we prepare our .gitlab-ci.yml file for
the evaluation runs.
CI/CD Component Configuration
We see that we have following notable changes/features in our code:
Include the jureap/jube component with a
v3branch of the exacb code.Changed the variant to
jedi.evaluation.jediandjedi.evaluation.jurecafor the evaluation runs appropriately.Extra Parameters
Pipeline Configuration
We further see that we have added a rule for the evaluation runs in our
.gitlab-ci.yml which looks as following
rules:
- if: $EXACB_JEDI_EVALUATION_RUN == "true"
This rule ensures that the run will only trigger if the variable
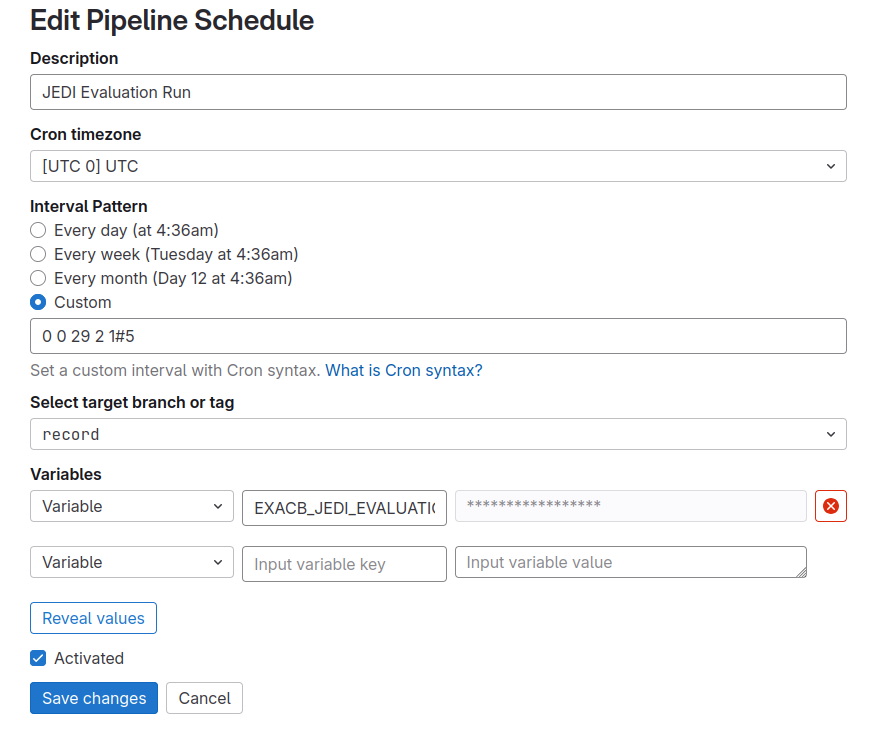
EXACB_JEDI_EVALUATION_RUN is set to true. We can further create
a pipeline schedule as shown below to trigger this run.
Reporting CI/CD component
Finally, we have added a reporting component to our .gitlab-ci.yml file which
looks likes the following. The complete reference for the component can be found
here. The component inclusion will generate the
report for the evaluation runs and upload it to the pages branch of the
repository as we can see here.
- component: gitlab.jsc.fz-juelich.de/exacb/catalog/jureap/jedi@v3
inputs:
prefix: "report.jedi.evaluation"
pipeline: [ "221418", "221415" ]
selector: [ "jedi.strong.tiny" , "jureca.strong.tiny" ]
workload_factor: [ "1.2" , "1.0" ]
prefix
The prefix input parameter is similar to the prefix input
parameter from the jureap/jube. It is
used to specify a unique namespace for the CI/CD jobs created by the component.
pipeline and selector
The pipeline input parameter takes an YAML array of pipeline IDs.
The pipeline combined with the selector input parameter is used to
select the jobs for which the report will be generated.
For example, in the above case, the report generator will choose the data
generated by the component with prefix jedi.strong.tiny in CI/CD
pipeline 221418 and the data generated by the component with prefix
jureca.strong.tiny in CI/CD pipeline 221415.
The workload_factor input parameter (as described here) is used to assign a workload
parameter for benchmarks. This is meant to be used in cases where the workloads
of the two benchmarks (the one on JEDI and the one on JURECA) are different.
Different benchmark workload means that the benchmarks are not directly
comparable. The workload factor is then used to scale the results of the
benchmark on JURECA to make them comparable to the benchmark on JEDI.